Приступая к третьему этапу моего буткемпа по науке о данных в школе Flatiron, я был очень рад узнать больше о различных моделях машинного обучения. Наша 3-я фаза сосредоточена на машинном обучении, и мы впервые попробовали модели классификации. Как помешанный на математике, я любил погружаться в математику, стоящую за всеми новыми моделями, которые теперь есть в нашем наборе инструментов для обработки и анализа данных. В частности, когда мы изучали нашу первую модель классификации (логистическую регрессию), я очень старался полностью понять математику, стоящую за этой моделью. В этом сообщении блога я расскажу об основных шагах по созданию модели логистической регрессии для бинарной классификации; набор данных, который я использовал, можно найти здесь. Набор данных был частью исследования, посвященного выживаемости пациентов с раком молочной железы, перенесших операцию в период с 1958 по 1970 год в больнице Биллингс Чикагского университета.
Почему логистическая регрессия?
Линейная регрессия — отличная модель для непрерывных переменных, но, как вы можете видеть на изображении ниже, прямая линия не помогает нам в бинарной классификации. По этой причине нам может помочь логистическая регрессия; логистическая регрессия сжимает все наши точки данных, чтобы они соответствовали значениям от 0 до 1.
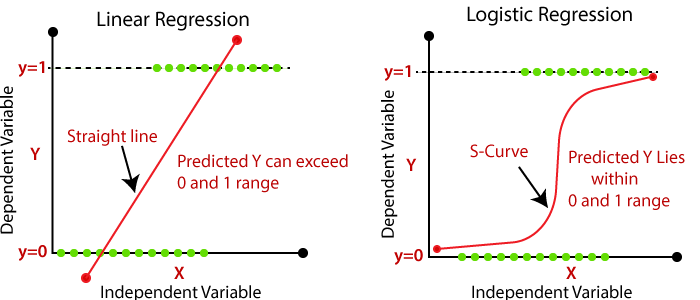
Фактическое значение в любой точке приведенной выше S-кривой — это вероятность того, что наша точка данных является членом нашего класса «1». Основываясь на этом значении вероятности, мы предсказываем метку нашей точки данных. Теперь я кратко расскажу о математике, лежащей в основе логистической регрессии.

Я считаю, что это изображение очень полезно для понимания трансформации, происходящей при выполнении логистической регрессии. Каждое значение x является независимой переменной, каждое w — это соответствующий вес, сгенерированный нашей моделью, а b — это точка пересечения нашей линейной модели. Другими словами, каждый w является коэффициентом для каждой независимой переменной. Теперь, когда у нас есть наша линейная модель, нам нужно преобразовать линию с помощью сигмовидной функции (уравнение y выше), чтобы преобразовать все значения в соответствии с диапазоном от 0 до 1. Наша линейная модель генерирует любое число от отрицательной бесконечности до положительной бесконечности на основе введите значения x. Член в знаменателе exp(-a) просто означает, что мы возводим натуральное число e в отрицательную a-ю степень. Когда а приближается к отрицательной бесконечности, этот член приближается к бесконечности, а у приближается к 0. Когда а приближается к положительной бесконечности, этот член приближается к 0, а у приближается к 1. Теперь, когда у нас есть базовое понимание математики, лежащей в основе логистической регрессии, мы можем перейти к коду.
Данные
Я использовал набор данных из репозитория машинного обучения UCI по показателям выживаемости среди пациентов с раком молочной железы, перенесших операцию в больнице Биллингс Чикагского университета. В наборе данных всего 4 столбца: возраст на момент операции, год, в котором была проведена операция (год-1900), количество положительных подмышечных узлов (лимфатические узлы в области подмышек, в которые распространился рак) и прожил ли пациент более 5 лет после операции. Во всех реальных сценариях вы хотели бы очистить свои данные, проверив фрейм данных на предмет любых отсутствующих значений и преобразовав данные из одного типа данных в другой. Однако этот набор данных легко доступен, в нем нет недостающих данных, поэтому мы можем использовать набор данных как есть.
Модель логистической регрессии
Библиотеки
# Import relevant libraries and packages
# Import visualization libraries and pandas/numpy to manipulate our data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# For logistic regression modeling steps
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import normalize, PolynomialFeatures
from sklearn.linear_model import LogisticRegression
# Libraries for classification metrics
from sklearn.metrics import confusion_matrix, plot_confusion_matrix,\
recall_score, log_loss, classification_report
Во-первых, мы импортируем все необходимые библиотеки для выполнения логистической регрессии. Документацию по модели логистической регрессии от sklearn можно найти здесь.
Библиотека pandas позволяет нам легко манипулировать нашими данными в виде фрейма данных. Dummy Classifier отлично подходит для создания базовой модели; эта модель имеет тенденцию быть чем-то очень простым, то есть всегда предсказывает класс большинства. Наш train_test_split быстро разделяет наши данные на наборы для обучения и тестирования. Этот шаг жизненно важен, потому что мы хотим протестировать нашу модель на действительно невидимых данных; разделив данные перед любым моделированием, мы можем обучить нашу модель с помощью обучающих данных перед тестированием нашей последней итерации модели на тестовом наборе. Два импорта из раздела предварительной обработки позволяют нам масштабировать наши данные и создавать новые функции из трех, которые у нас есть. Модель логистической регрессии на самом деле является частью GLM sklearn (обобщенная линейная модель), потому что мы все еще вычисляем линию наилучшего соответствия; линия наилучшего соответствия соответствует преобразованию y. Наконец, мы импортируем несколько метрик классификации из sklearn для оценки наших моделей.
Подготовка данных
# Load in our dataset and inspect. We need to add column names for the dataset as well
colnames = ['age_during_op', 'year_of_op', 'pos_ax_nodes', 'death_5yr']
df = pd.read_csv('./data/haberman.csv', names=colnames, header=None)
df.head()
Приведенный выше код просто считывает наш набор данных из файла .csv. В файле .csv не было имен столбцов, поэтому я добавил их при создании фрейма данных.
# The original dataset used 2’s and 1’s to denote survival past 5 # years. We need to convert these to 1’s and 0's
# A 1 corresponds to the patient dying within 5 years of the # operation
df['death_5yr'] = df['death_5yr'].map({1:0, 2:1})
# First, we'll create our test_train split to ensure no data leakage occurs in our model
X = df.drop('death_5yr', axis=1)
y = df['death_5yr']
# specifying a random_state ensures that anyone else running my code # can replicate my results
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Теперь, когда у нас есть данные, разделенные на набор для обучения и тестирования, мы можем создать нашу базовую модель.
Моделирование
# Create a dummy model that always predicts the majority class. # (survived more than 5 years) # This is our baseline model # Instantiate the model, select strategy to always select majority dummy_model = DummyClassifier(strategy='most_frequent') # Fit our model to our training data dummy_model.fit(X_train, y_train) # View the confusion matrix plot_confusion_matrix(estimator=dummy_model, X=X_train, y_true=y_train);

Изображение выше — это матрица путаницы для нашей фиктивной модели. По вертикальной оси находится истинная метка, а по горизонтальной оси — наша предсказанная метка. Как и ожидалось, мы всегда предсказывали, что пациент выживет. Отличный способ разрушить матрицу путаницы — думать о ней с точки зрения ложных срабатываний, истинных срабатываний, ложноотрицательных и истинно отрицательных результатов. На изображении ниже показан общий формат матрицы путаницы с уравнениями для ключевых показателей.

Наша полнота/чувствительность будет важной метрикой для этого бизнес-кейса, потому что мы хотим знать, насколько эффективна наша модель в прогнозировании истинных положительных результатов (т. е. единиц). С точки зрения непрофессионала, отзыв можно определить как: для всех точек данных в положительном классе, сколько правильно идентифицировала наша модель. Что касается конкретно этих данных, то какую долю мы правильно определили для всех больных раком молочной железы, умерших в течение 5 лет после операции.
Давайте создадим нашу первую модель логистической регрессии!
# Normalize both X data sets to weight every predictor equally X_train_norm = normalize(X_train) X_test_norm = normalize(X_test) # Instantiate the model log_model = LogisticRegression(random_state=42) # Fit the model to our normalized training data log_model.fit(X_train_norm, y_train) # View the confusion matrix plot_confusion_matrix(estimator=log_model, X=X_train_norm, y_true=y_train) # Calculate our recall score recall_score(y_train, log_model.predict(X_train_norm))

Как мы видим, наша первая модель работает почти так же, как и фиктивная модель. Наш отзыв в данном случае составляет всего 1,6%! Эта модель исключительно плохо предсказывает истинные положительные результаты (пациенты, которые умерли в течение 5 лет). Далее мы попробуем настроить гиперпараметры, которые определены при создании экземпляра нашей модели.
«C» является обратной силой регуляризации. Это означает, что по мере увеличения C сила регуляризации уменьшается. Регуляризация используется для предотвращения переобучения. Решатель «liblinear» хорошо работает для небольших наборов данных, поэтому мы попробуем использовать этот решатель, а не по умолчанию. Для получения дополнительной информации о гиперпараметрах для логистической регрессии вы можете просмотреть документацию, на которую я ссылался выше.
# Instantiate the model log_model = LogisticRegression(C=100000, solver='liblinear', random_state=42) # Fit the model to our training data log_model.fit(X_train_norm, y_train) # View the confusion matrix for our first logistic regression model plot_confusion_matrix(estimator=log_model, X=X_train_norm, y_true=y_train); # Calculate our recall score recall_score(y_train, log_model.predict(X_train_norm))

Эта модель значительно улучшила наши результаты. Наш показатель отзыва теперь составляет 29%! Это значение по-прежнему намного ниже, чем нам хотелось бы, но мы видим улучшения. Учитывая, что в нашем наборе данных было только 3 столбца-предиктора, мы можем использовать пакет PolynomialFeatures для создания дополнительных переменных-предикторов на основе 3-х, которые у нас есть. Документацию по PolynomialFeatures можно найти здесь.
# Given that we only have 3 columns to predict our target, we will # use the Polynomial Features class from sklearn to increase the # number of input features # Instantiate transformer with degree 3 pf = PolynomialFeatures(degree=3) # Fit the transformer to our training X data. Transform both training and testing sets pf.fit(X_train) X_train_poly = pf.transform(X_train) X_test_poly = pf.transform(X_test) # instantiate the model log_poly_model = LogisticRegression(C=10000, solver='liblinear', random_state=42, max_iter=10000) # fit the model log_poly_model.fit(X_train_poly, y_train) # view confusion matrix plot_confusion_matrix(log_poly_model, X_train_poly, y_train); # calculate our recall score recall_score(y_train, log_poly_model.predict(X_train_poly))

С нашей новейшей моделью мы достигли показателя отзыва 40%. Еще одна тенденция, которую можно проследить из итерации нашей модели, заключается в том, что количество ложных срабатываний увеличивается. Это означает, что, повышая показатель отзыва, мы снижаем точность нашей модели. Этот компромисс будет смещаться в сторону той или иной метрики в зависимости от понимания бизнес-проблемы/набора данных, которые вы исследуете. Поскольку это относительно простая модель логистической регрессии, мы продолжим и будем рассматривать эту модель как нашу окончательную модель на данный момент. Давайте оценим на нашем тестовом наборе!
# Given that this is our best model so far, we can run the model on # our test data set # View our confusion matrix plot_confusion_matrix(log_poly_model, X_test_poly, y_test); # Calculate our recall score recall_score(y_test, log_poly_model.predict(X_test_poly))

Наш отзыв на наборе тестовых данных составил всего 17%, а общая точность модели составила ~ 66%. Учитывая, что точность модели на нашем наборе обучающих данных была значительно лучше, мы можем сказать, что наша модель подходит для обучающих данных.
Следующие шаги
Логистическая регрессия может быть прекрасным инструментом для решения задач бинарной классификации (а также задач множественной классификации!). Мы создали эту модель, чтобы попытаться предсказать, выживет ли пациентка с раком молочной железы более 5 лет после операции. Чтобы продолжить работу с этими данными, я попытаюсь использовать другие методы классификации (например, деревья решений, kNN и т. д.), чтобы создать лучшую модель. Ссылку на мой файл блокнота jupyter можно найти здесь. Обязательно периодически заходите в мой репозиторий, так как я продолжу работу с этим набором данных с целью воспроизвести 80%!
Не стесняйтесь обращаться с любыми вопросами и удачного кодирования. :)