
Алгоритм Adaboost в машинном обучении — методы ансамбля
В этой статье мы увидим, что такое алгоритм AdaBoost, как работают алгоритмы AdaBoost с помощью примера и реализации алгоритма AdaBoost на python.
В прошлом году алгоритмы бустинга приобрели огромную популярность в конкурсе Kaggle. Многие Kaggler выиграли соревнование, используя эти алгоритмы повышения для достижения более высокой производительности. Алгоритм Adaboost является примером алгоритма повышения. Мы подробно обсудим алгоритм AdaBoost.
Типы ансамблевых методов:
- Методы ансамбля можно разделить на две группы: основанные на базовых обучающихся.
Последовательные учащиеся:
Там, где базовые учащиеся генерируются последовательно, например, Adaptive Boosting (AdaBoost), последовательное создание базовых учащихся способствует зависимости между базовыми учащимися. Затем производительность модели повышается за счет присвоения более высоких весов предыдущим учащимся.
Параллельные учащиеся:
Там, где базовые обучающиесягенерируются в параллельном формате, например, в случайном лесу, случайный лес содержит множество деревьев решений. Параллельное создание базовых учеников способствует независимости между ними.
- Основываясь на типах базовых учащихся, метод ансамбля можно разделить на две группы.
- Метод однородного ансамбля использует один и тот же тип базового учащегося на каждой итерации.
- Метод гетерогенного ансамбля использует разные типы базового учащегося на каждой итерации.
Что такое алгоритм AdaBoost?
- AdaBoost или Adaptive Boosting — это один из методов повышения ансамбля, предложенный Йоавом Фройндом и Робертом Шапире в 1996 году. Его можно использовать как для задач классификации, так и для регрессии. AdaBoost — это итеративный ансамблевый метод. Он создает сильный классификатор, объединяя несколько слабых классификаторов. Окончательный классификатор представляет собой взвешенную комбинацию нескольких слабых классификаторов. Он соответствует последовательности слабых учеников на различных взвешенных данных обучения. Если прогноз с использованием первого ученика неверен, он придает больший вес наблюдению, которое было неверно предсказано. Будучи итеративным процессом, он продолжает добавлять учащихся до тех пор, пока не будет достигнут предел количества моделей или точности. Вы можете увидеть этот процесс, представленный на рисунке AdaBoost.

- С AdaBoost можно использовать любой базовый классификатор. Этот алгоритм не склонен к переобучению. AdaBoost легко реализовать. Одним из недостатков AdaBoost является то, что на него сильно влияют выбросы, потому что он пытается идеально соответствовать каждой точке. Это вычислительно медленнее по сравнению с XGBoost.
- Для простого объяснения сначала AdaBoost выбирает случайным образом обучающее подмножество и придает каждому наблюдению равный вес. Если прогноз с использованием первого ученика неверен, он придает больший вес наблюдению, которое было неверно предсказано. Модель итеративно обучается, выбирая обучающий набор на основе точного прогноза последнего обучения. Будучи итеративным процессом, модель добавляет несколько учащихся до тех пор, пока не будет достигнут предел количества моделей или точности.
- Любой алгоритм машинного обучения может использоваться в качестве базового классификатора, если он принимает веса в обучающем наборе.
- AdaBoost должен соответствовать двум условиям:
- Классификатор должен обучаться в интерактивном режиме на различных взвешенных обучающих примерах.
- На каждой итерации он пытается обеспечить идеальное соответствие этим примерам, сводя к минимуму ошибку обучения.
Интуиция алгоритма AdaBoost:
- Он работает в следующих шагах:
- Первоначально Adaboost случайным образом выбирает обучающую подгруппу.
- Итеративно обучает модель машинного обучения AdaBoost, выбирая обучающий набор на основе точного прогноза последнего обучения.
- Итеративно обучает модель машинного обучения AdaBoost, выбирая обучающий набор на основе точного прогноза последнего обучения.
- Кроме того, он присваивает вес обученному классификатору на каждой итерации в соответствии с точностью классификатора. Более точный классификатор получит больший вес.
- Этот процесс повторяется до тех пор, пока полные обучающие данные не будут соответствовать без какой-либо ошибки или не будут достигнуты заданное максимальное количество оценок.
- Чтобы классифицировать, проведите «голосование» по всем созданным вами алгоритмам обучения.
- Интуицию можно изобразить с помощью следующей схемы:

Пример того, как работает AdaBoost:
Прежде всего, мы должны узнать о работе наддува. Он создает n деревьев решений, когда мы обучаем данные. При создании первого дерева решений или модели обучающий пример неправильно классифицировал первый режим, и тогда первая модель имеет больший приоритет. Только эти обучающие примеры отправляются в качестве входных данных для второй модели. Этот процесс будет продолжаться до тех пор, пока мы не укажем количество базовых учащихся, которых хотим создать в нашей модели. Помните, что повторение обучающего примера разрешено для всех методов бустинга.

На приведенном выше рисунке показано, что когда создается первая модель и алгоритм замечает ошибки первой модели, неправильно классифицированный обучающий пример дается в качестве входных данных для следующей модели. Этот процесс повторяется снова и снова, пока заданное условие не будет выполнено. Если вы посмотрите на приведенный выше рисунок, то увидите, что существует n моделей, созданных путем минимизации ошибок предыдущей модели. Так работает повышение. Модели 1,2, 3,…, N являются отдельными моделями, известными как деревья решений. Все методы ансамбля работают по одной и той же концепции.
Теперь мы знаем концепцию бустинга, будет удобно разбираться в алгоритме AdaBoost. Давайте углубимся в работу алгоритмов Adaboost. Когда используется алгоритм случайного леса, алгоритм создает n деревьев. Он создал идеальные деревья, состоящие из начального узла с несколькими узлами-листьями. Некоторые деревья решений могут быть больше других деревьев, но в случайном лесу нет фиксированной глубины или длины. Но с Adaboost это не так. В AdaBoost алгоритм создает только узел с двумя листьями, и это известно как пень решения.
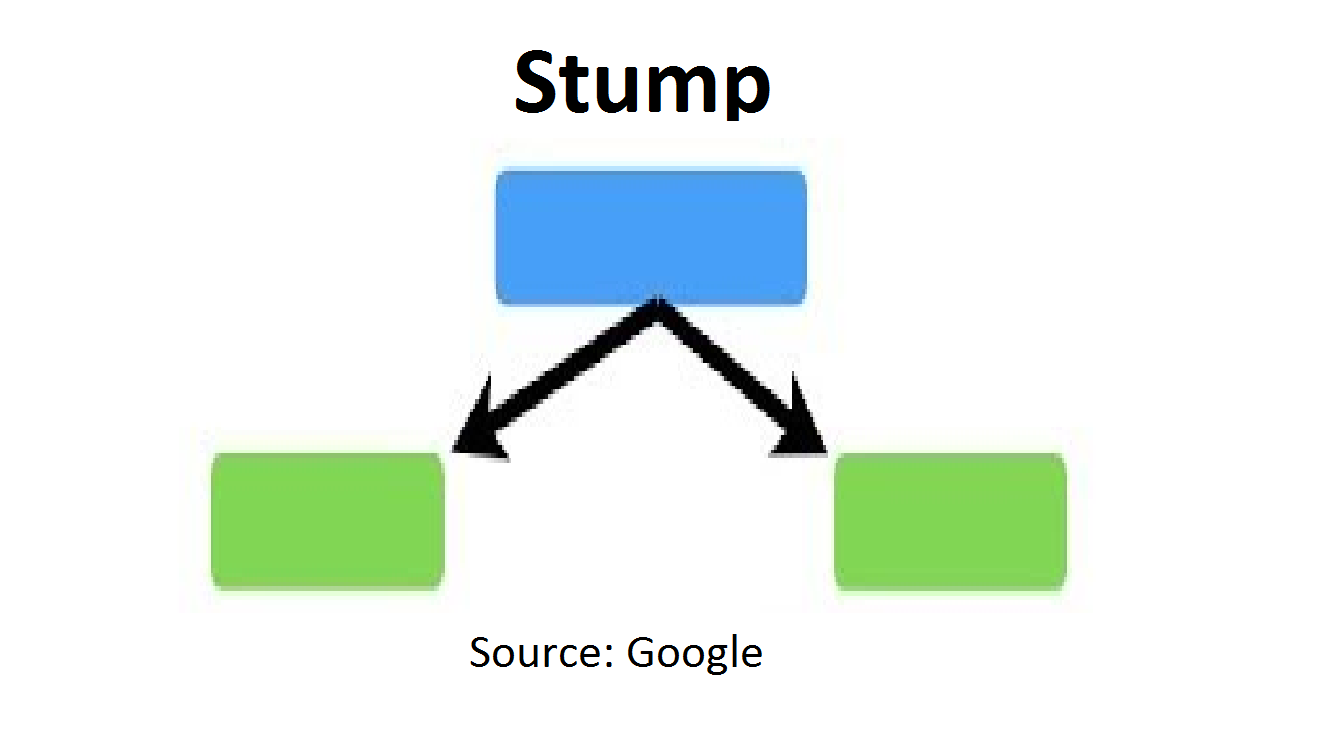
Вышеприведенное изображение представляет собой один пень решения. Мы можем ясно видеть, что он имеет только один узел только с двумя листьями. Эти пни принятия решений являются слабыми учениками, а повышающие алгоритмы делают этих маленьких учеников сильными учениками. Порядок пней решений имеет большое значение в алгоритмах AdaBoost. Ошибка первого пня решения отражала то, как создается другой пень решения. Приведем пример понимания.

Здесь у нас есть пример набора данных, который состоит всего из трех функций, а выходные данные представлены в двоичном формате. Поскольку вывод находится в двоичном формате, это становится проблемой классификации. В реальной жизни набор данных может иметь множество обучающих примеров и множество функций в наборе данных. Предположим, у нас есть 5 обучающих примеров для пояснений. Выходные данные представлены в двоичном формате, и здесь это «Да» или «Нет». Всем этим обучающим примерам будет присвоен вес выборки. Используемая формула: W=1/N, где N — количество записей для присвоения некоторых весов. В этом наборе данных всего 5 обучающих примеров, поэтому изначально вес выборки становится равным 1/5. Каждый ряд получает одинаковый вес. Это 1/5.
Шаг 1 — Создание первого базового ученика
Теперь пришло время создать первую базовую обучающую программу. Алгоритм принимает первую функцию, например. признак 1 и создает первый культ решения f1. Затем он создаст такое же количество пней решений, как и количество функций. Этот случай создаст 3 пня решения, потому что в этих данных есть только 3 переменные. Все эти пни решений создадут три дерева решений и базовую модель обучаемого. Алгоритм AdaBoost выберет только один. При выборе базового ученика есть два свойства: Джини и Энтропия. Мы должны рассчитать Джини или Энтропию так же, как это было рассчитано для деревьев решений. Пень решения заключается в том, что наименьшее значение будет считаться первым базовым учеником. На приведенном ниже рисунке все 3 пня решения могут быть сделаны с 3 переменными. Число под листьями представляет собой правильно и неправильно классифицированный пример обучения. Пень с наименьшей энтропией или Джини будет выбран для базового ученика. Представим, что показатель энтропии наименьший для культя решения. Итак, давайте возьмем решение 1, то есть функцию 1 в качестве нашего первого базового ученика.


Здесь функция f1 правильно классифицировала 2 наблюдения и 1 неправильно. Строка на картинке, отмеченная красным, неправильно классифицирована. Мы будем вычислять общую ошибку только для этой строки.
Шаг 2 — Расчет общей ошибки (TE)
Общая ошибка представляет собой сумму всех ошибок в классифицированном обучающем примере для выборочных весов. В нашем случае есть только 1 ошибка, поэтому Total Error (TE) = 1/5.
Шаг 3 — Расчет производительности пня
Формула для расчета эффективности решения Stump: –

Где ln — натуральный журнал, а TE — общая ошибка.
В нашем примере общая ошибка составляет 1/5. Сохраняя значение общей ошибки в приведенной выше формуле, мы получаем значение эффективности решения Stump как 0,693. Вы, должно быть, задаетесь вопросом, почему важно определить TE и производительность культи? Правильно, мы должны обновить вес выборки, прежде чем переходить к следующей модели. Только неправильный обучающий пример/неправильно классифицированные записи получили большее предпочтение, чем правильно классифицированный обучающий пример. Таким образом, только неправильные записи из дерева решений или пня решения передаются другому пню решения. В AdaBoost обе записи были пропущены, и неправильные обучающие примеры повторяются чаще, чем правильный обучающий пример. Мы должны увеличить вес выборки для неправильно классифицированных обучающих примеров и уменьшить вес выборки для правильно классифицированного обучающего примера. На следующем шаге мы будем обновлять веса в зависимости от производительности пня решения.
Шаг 4 — Обновление весов
Для неправильно классифицированного обучающего примера формула выглядит так:
Новый вес выборки = вес выборки * e^(производительность)
В нашем случае вес выборки = 1/5, поэтому 1/5 * e^ (0,693) = 0,399
А для правильно классифицированного обучающего примера используем ту же формулу со знаком минус с производительностью. Вес правильно классифицированного тренировочного примера будет уменьшен по сравнению с неправильно классифицированным. Формула:
Вес выборки = Вес выборки * e^- (производительность)
Помещая значения, 1/5 * e^-(0,693) = 0,100


Обновленный вес для всего тренировочного примера можно увидеть на рисунке. Общая сумма всех весов должна быть 1. Но мы видим, что общий обновленный вес всех обучающих примеров равен не 1, а 0,799. Чтобы сделать общую сумму равной 1, мы должны разделить каждый обновленный вес на общую сумму обновленного веса. Например, если обновленный вес равен 0,399, мы должны разделить его на 0,799, например 0,399/0,799=0,50.
0,50 можно определить как нормализованный вес. Мы можем видеть весь нормализованный вес на изображении ниже, и общая сумма приблизительно равна 1.
Шаг 5 — Создание нового набора данных
Теперь мы можем создать новый набор данных из предыдущего. В этом новом наборе данных частота неправильно классифицированных обучающих примеров будет больше, чем правильно классифицированных. При анализе этих нормализованных весов мы должны создать новый набор данных, и этот набор данных будет основан на нормализованных весах. Вероятно, он выберет неправильные обучающие примеры для учебных целей. Это будет второе дерево решений или пней решений. Чтобы создать новый набор данных на основе нормализованного веса, алгоритм разделит его на период.

Наш первый диапазон — от 0–0,13. Второй диапазон: 0,13–0,63 (0,13+0,50). Третий диапазон: 0,63–0,76 (0,63+0,13) и т. д. После этого алгоритм выполнит 5 итераций, чтобы выбрать разные записи из более старого набора данных. Представьте, в 1-й итерации. Алгоритм примет случайное значение 0,46. Затем он пойдет и увидит, в какой период упадет значение, и выберет этот обучающий пример в новом наборе данных, затем снова выберет случайное значение и увидит, в каком периоде он находится, а затем выберет этот обучающий пример для нового набор данных, и тот же процесс повторяется для 5 итераций.
Существует вероятность того, что несколько раз будут выбраны неправильные обучающие примеры. Это будет новый набор данных. На изображении ниже видно, что строка номер 2 была выбрана несколько раз из более старого набора данных, поскольку эта строка неправильно классифицирована в предыдущем наборе данных.

Основываясь на новом наборе данных, алгоритм снова создаст новое дерево решений или пень, и он будет повторять тот же процесс с шага 1, пока он последовательно не пройдет через все пни решений и не обнаружит, что существует минимальная ошибка по сравнению с нормализованным весом, который мы имели в нашем начальном шаге.
Реализация AdaBoost на Python
- Теперь мы подошли к части реализации алгоритма AdaBoost в Python.
- Первым шагом является загрузка необходимых библиотек.
Импорт библиотек

Загрузить набор данных

ЭДА

Просмотр сводки фрейма данных

Мы видим, что в наборе данных нет пропущенных значений.
Объявить вектор признаков и целевую переменную


Разделите набор данных на обучающий набор и тестовый набор

Создайте модель AdaBoost

Оценить модель
Давайте оценим, насколько точно классификатор или модель может предсказать тип сортов.

- В данном случае мы получили точность 86,67%, что будет считаться хорошей точностью.
Дальнейшая оценка с помощью базовой оценки SVC
- Для дальнейшей оценки мы будем использовать SVC в качестве базовой оценки следующим образом:

- В этом случае мы получили уровень классификации 91,11%, что считается выдающейся точностью.
- В этом случае базовый оценщик SVC получает более высокую точность, чем базовый оценщик дерева решений.
Преимущества и недостатки AdaBoost
Преимущества заключаются в следующем:
- AdaBoost легко реализовать.
- Он итеративно исправляет ошибки слабого классификатора и повышает точность за счет объединения слабых учеников.
- Мы можем использовать множество базовых классификаторов с AdaBoost.
- AdaBoost не склонен к переоснащению.
Недостатки следующие:
- AdaBoost чувствителен к шумовым данным.
- На него сильно влияют выбросы, потому что он пытается идеально соответствовать каждой точке.
- AdaBoost медленнее по сравнению с XGBoost.
Результаты и заключение
- мы обсудили классификатор AdaBoost.
- Мы обсудили, как классифицируются базовые учащиеся.
- Затем мы переходим к обсуждению интуиции, лежащей в основе классификатора AdaBoost.
- Затем мы представляем реализацию классификатора AdaBoost с использованием набора данных iris.
- Наконец, мы обсудили преимущества и недостатки классификатора AdaBoost.